hewking.top
hewking's blog
llm 原理
Author: hewking
Labels: blog
Created: 2025-02-13T13:44:25Z
Link and comments: https://github.com/hewking/blog/issues/52
llm 原理
LLM 预训练
步骤:
- 数据集
- token 序列化
- 预训练:神经网络训练
- 推理
AI News
参考
- Andrej Karpatht: Deep Dive into LLMs like ChatGPT
- HuggingFaceFW/fineweb: 数据集
- Transformer Neural Net 3D visualizer LLM 可视化
- token 序列化示例
- karpathy 复现 GPT-2 示例
- Llama 3 paper from Meta
- hyperbolic: 云端大模型 demo 和 api
- HuggingFace inference playground
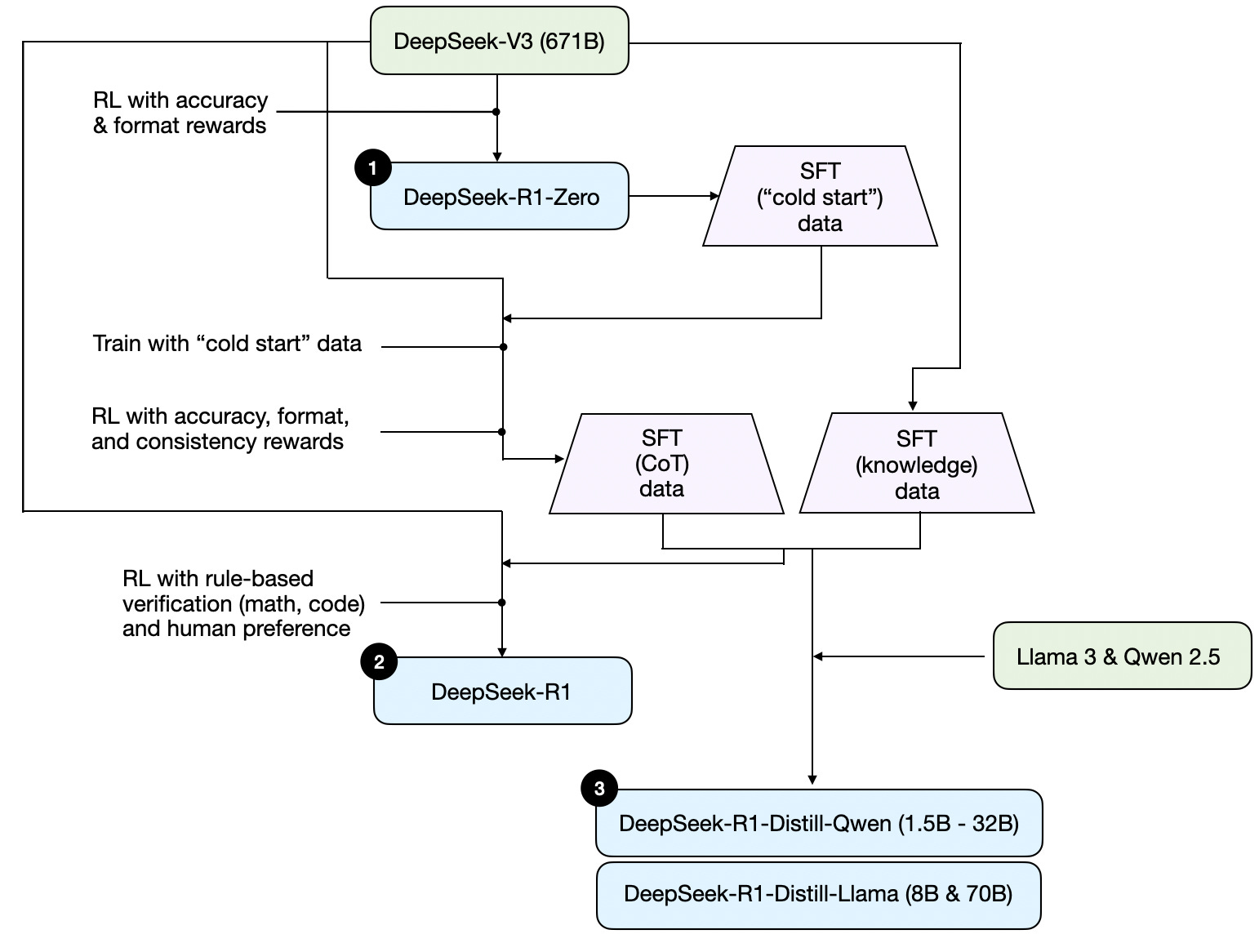
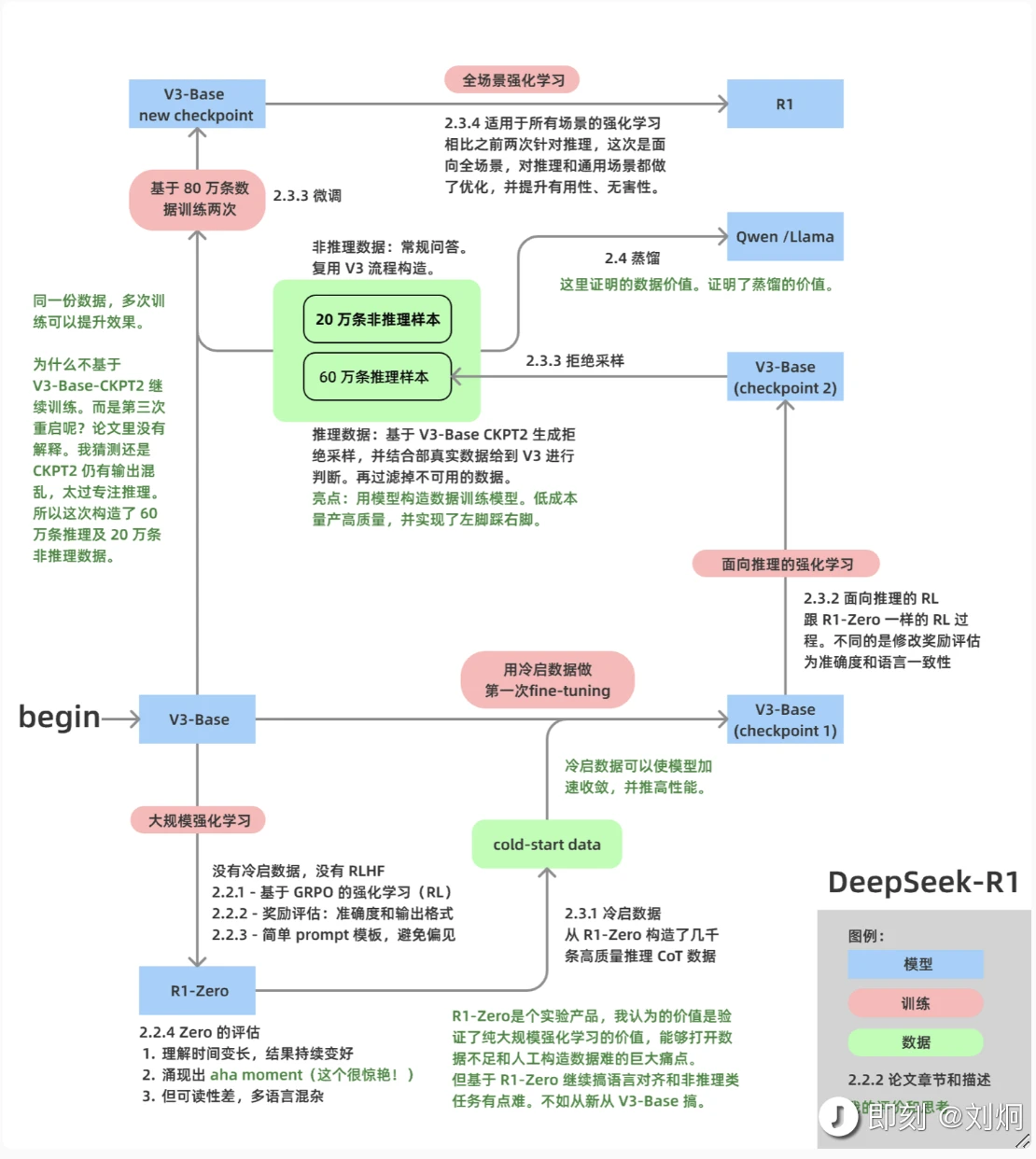
- DeepSeek-R1 paper
- TogetherAI Playground for open model inference
- LM Arena for model rankings
- AI News Newsletter
- LMStudio for local inference
- 最好的致敬是学习:DeepSeek-R1 赏析
- Understanding Large Language Models
- Intro to Large Language Models
- 模型文件本质:参数文件(pytorch: .pt 文件) + run.c 运行代码
- 参数文件:有损压缩互联网数据为神经网络
- 神经网络:数据之间会形成规律
- 预训练:BaseModal
- 微调: Assistant Modal
- 模型的幻觉:(模型输出时,类似在做梦)
- RL: HFRL, RL
- Thingking , System1, System2
- 多模态
- Scaling Law
- 大模型的未来
- 模型安全
- 视频资源
- Tramsforms 原理
- Attention Is All You Need
-
[Attention in transformers, step-by-step DL6](https://www.youtube.com/watch?v=eMlx5fFNoYc) -
[Visualizing transformers and attention Talk for TNG Big Tech Day ‘24](https://www.youtube.com/watch?v=KJtZARuO3JY)
- Understanding DeepSeek-R1